
FONDEMENTS DE L’IA ET TERMINOLOGIE
Ce chapitre présente les bases conceptuelles pour comprendre l’intelligence artificielle (IA) dans une perspective pédagogique et linguistique. Il donne aux enseignant.e.s de langues, même sans formation technique, des repères pour saisir les principes, les limites, la terminologie clé et les implications de l’IA en enseignement supérieur. L’objectif n’est pas de devenir des personnes expertes en informatique, mais de développer une compréhension fonctionnelle, une lecture critique des sorties, une maîtrise terminologique utile aux apprenant.e.s, et une capacité d’analyse de l’influence de l’IA sur les savoirs linguistiques (Abécédaire de l’IA, 2024; Vangrunderbeeck, 2024).
1.1. Qu’est-ce que l’intelligence artificielle ?
Les définitions de l’IA ont évolué depuis les années 1950. Dans les ressources pédagogiques récentes, l’IA est présentée comme un ensemble de technologies qui simulent ou automatisent certaines facultés cognitives humaines (perception, classification, prédiction, recommandation), en s’appuyant sur des données et des algorithmes (Abécédaire de l’IA, 2024; de la Higuera & Iyer, 2024).
Il existe trois grandes catégories d’IA :
- IA faible[1] : conçue pour une tâche spécifique (moteurs de recherche, correcteurs, traducteurs).
- IA forte : hypothétique; une IA qui raisonnerait comme un humain (non existante à ce jour).
- IA générale (AGI) : autre hypothèse d’une IA autonome et polyvalente (non atteinte).
Ce qui nous intéresse présentement est l’intelligence artificielle générative ou l’IAg (consultez Tableau 1 sur les techniques utilisées). C’est un sous-domaine de l’IA faible qui désigne un ensemble de technologies capables de créer ou de produire de nouveaux contenus (texte, image, audio, vidéo, code) à partir d’immenses bases de données et de larges modèles de langage (de la Higuera & Iyer, 2024). Elle se distingue des modèles prédictifs classiques en produisant des sorties nouvelles selon des régularités apprises dans les données (Moorhouse & Wong, 2025; UNESCO, 2025).
Tableau 1. Techniques utilisées dans l’IA générative (Unesco, 2024)
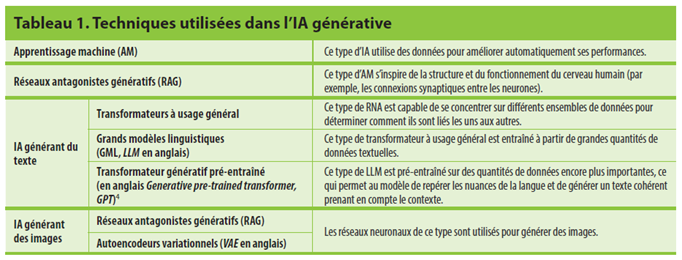
La qualité des productions générées par l’IAg dépend de trois éléments essentiels (Abécédaire de l’IA, 2024; UNESCO, 2024; Réseau Canopé, 2025). Premièrement, les données d’entraînement influencent directement la précision, la diversité linguistique et les biais des réponses. Deuxièmement, le modèle lui-même – les grands modèles linguistiques (GML) – repose sur la détection de régularités statistiques sans véritable compréhension du contenu au sens humain. Troisièmement, la requête (ou prompt) joue un rôle déterminant : son contexte, son intention et son format conditionnent la pertinence de la réponse.
Ces trois éléments s’articulent avec le fonctionnement interne de l’IAg : l’entraînement, où le modèle observe des millions de textes pour inférer des régularités ; l’interprétation, où il analyse la requête pour anticiper la réponse attendue ; et la génération, où il prédit mot après mot jusqu’à produire un message complet. Cette approche probabiliste explique pourquoi les réponses peuvent paraître convaincantes sans refléter une compréhension réelle du monde, d’où la nécessité d’une validation humaine et d’un usage critique (UNESCO, 2025; Abécédaire de l’IA, 2024).
En tant qu’enseignant.e.s des cours de langues, nous n’avons pas besoin d’un bagage technique avancé, mais plutôt d’une compréhension fonctionnelle et critique, fondée sur l’usage réel et sur la pédagogie.
1.2. Les grands modèles linguistiques (GML)
Les GML sont des réseaux neuronaux à grande échelle qui génèrent du contenu et manipulent du texte en tenant compte des relations contextuelles entre tokens afin de produire des résultats statistiquement probables (Fui-Hoon Nah et al., 2023 dans Moorhouse & Wong, 2025). Pour l’enseignement des langues, ils offrent des capacités de génération et d’analyse utiles, mais standardisent souvent le style (Abécédaire de l’IA, 2024; Moorhouse & Wong, 2025). Moorhouse et Wong (2025) propose trois catégories de classement des outils d’IAg pour l’enseignement des langues :
- Chatbots conversationnels : Interfaces basées sur des GML permettant des échanges contextualisés, la création de contenus variés et la traduction multimodale (p. 6-13).
- Générateurs visuels, audio et vidéo : Produisent des images, sons ou vidéos à partir de requêtes en langage naturel, souvent via des GML (p. 13-14).
- Outils intégrant des fonctions d’IAg et outils spécialisés : Applications existantes ou dédiées qui automatisent des tâches pédagogiques (p. ex., Kahoot!, MagicSchool.ai) (p. 14).
Les enseignant.e.s doivent garder à l’esprit que les modèles d’IAg ne comprennent pas réellement le sens des textes qu’ils produisent : ils se basent sur des probabilités pour prédire les mots suivants. Cette approche statistique comprend plusieurs limites techniques qui exigent une posture critique et une transparence envers les apprenant.e.s (UNESCO, 2025; de la Higuera & Iyer, 2024; Quiquempois & Goémé, 2025). Par exemple, le contenu généré peut entraîner des ‘hallucinations’, c’est-à-dire des erreurs ou des informations inventées ou fausses, parfois présentées avec assurance. De plus, ces modèles tendent à uniformiser la langue, en privilégiant des registres standardisés et en réduisant la diversité des variétés du français. Nous devons aussi rester conscients des biais qui peuvent émerger, ce qui signifie le renforcement de stéréotypes et standardisation linguistique influencées par les données d’entraînement. Plus ces outils sont utilisés, en particulier par nos étudiant.e.s, plus ils risquent de développer une dépendance à ces systèmes, ce qui peut limiter leur capacité à raisonner de manière autonome. Ce qui demeure également incertain, c’est la manière dont la propriété intellectuel et les informations privées sont exploitées par ces GML, ce qui nous oblige à rester constamment vigilants et sur nos gardes. Ainsi, ces limites soulignent l’importance de la validation humaine et de l’esprit critique dans l’usage pédagogique des IAg (Moorhouse & Wong, 2025).
1.3. L’ingénierie de la requête (prompting)

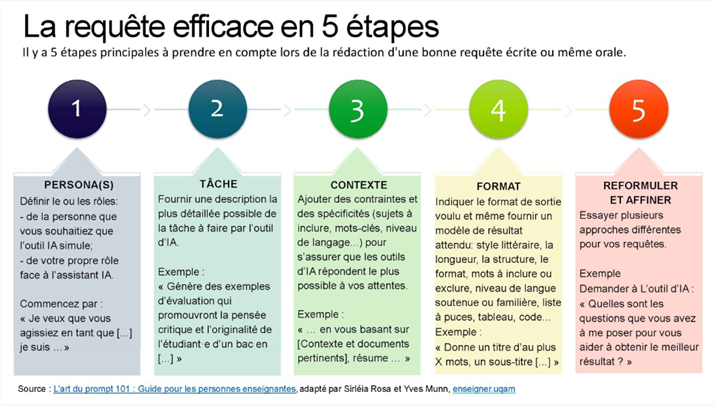
Source : Vangrunderbeeck (2024)
Le prompting consiste à formuler une requête claire et contextualisée (niveau, objectif, public, format) pour obtenir une sortie utile. Les cadres issus de la formation des enseignant.e.s insistent sur la clarté, la structure et l’itération, ainsi que sur la sécurité des données (Vangrunderbeeck, 2024; Nouveau-Brunswick, 2024).
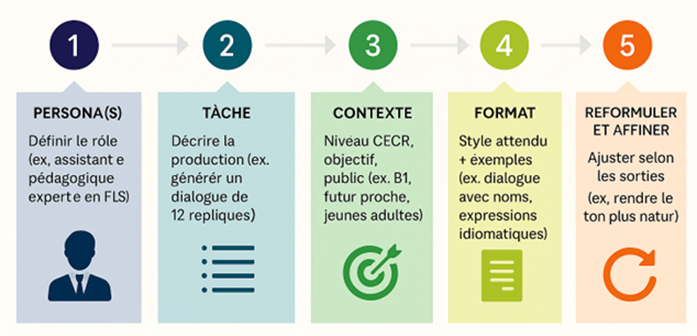
Pour celles et ceux qui n’ont pas tendance à utiliser des outils d’IA, en particulier Microsoft Copilot, ou qui n’ont pas encore maîtriser l’art du prompt, l’Université d’Ottawa offre des recommandations pour la composition des requêtes. Vous pouvez aussi faire appel au processus en 5 étapes :
Exemple de Copilot 2025
1.4. IA pour l’enseignement des langues
(UNESCO, 2025; Moorhouse & Wong, 2025; Abécédaire de l’IA, 2024)
L’intelligence artificielle offre des opportunités pédagogiques considérables pour l’enseignement des langues : elle permet de simuler des conversations contextualisées (du niveau A2 à C1), de soutenir l’apprentissage lexical par des cartes sémantiques, de créer du matériel multimodal (audio, vidéo, images) et de personnaliser les exercices selon le profil des apprenant.e.s. Elle favorise également le développement de la littératie numérique et de la capacité à valider les sources. Ces usages doivent toutefois rester alignés sur les objectifs du cours et préserver l’agentivité des apprenant.e.s
Cependant, il est essentiel de rappeler ce qu’elle n’est pas: elle ne comprend pas le sens des énoncés, n’a ni intention, ni émotion, ni conscience, et ne sait pas si elle se trompe. Les GML reposent sur des prédictions statistiques et peuvent produire des biais ou des hallucinations. L’IA ne remplace donc pas l’expérience pédagogique humaine, ni notre rôle critique dans la médiation, la validation et la contextualisation des apprentissages.
En pratique, l’IA doit être utilisée comme un soutien encadré plutôt qu’un substitut. L’apprentissage de la rédaction de requêtes efficaces, la vigilance face aux biais et la formation à l’usage critique des outils, ainsi qu’une compréhension de base du fonctionnement des systèmes sont des conditions indispensables pour que l’IA enrichisse l’enseignement du FLS sans compromettre l’autonomie cognitive des apprenant.e.s.
[1] Les outils actuels (ChatGPT, Claude, Gemini, Copilot) relèvent de l’IA faible (Vangrunderbeeck, 2024; UNESCO, 2025).